“Help! I have a million images and I’m sure there are duplicates, but which are they?”
There are numerous situations in which you may need to identify duplicate images in collections, for example:
- to ensure that a page or book has not been digitised twice
- to discover whether a master and service set of digitised images represent the same set of originals
- to confirm that all scans have gone through post-scan image processing.
Checking to identify duplicates manually is a very time-consuming and error-prone process. You need a tool to help you – Matchbox.
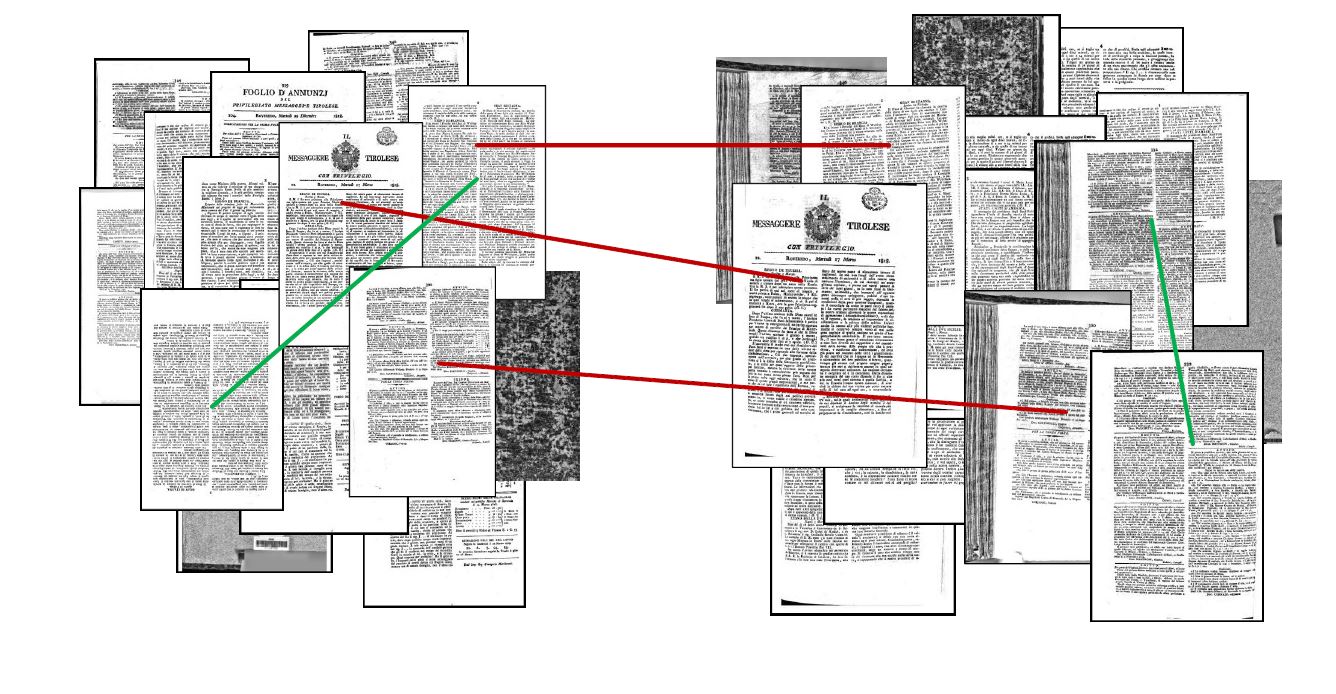 Green line = duplicate detected within collection; Red line = duplicate detected across collections
Green line = duplicate detected within collection; Red line = duplicate detected across collections
What is Matchbox?
Matchbox is an open source tool which:
- provides decision-making support for duplicate image detection in or across collections
- identifies duplicate content, even where files are different (in format, size, rotation, cropping, colour-enhancement etc.), and if they have been scanned from different original copies of the same publication
- applies state-of-the art image processing works where OCR will not, for example images of handwriting or music scores
- is useful in assembling collections from multiple sources, and identifying missing files.
What are the benefits of Matchbox?
- Automated quality assurance
- Reduced manual effort and error rate
- Saved time
- Lower costs, e.g. storage, effort
- Open source, standalone tool. Also as Taverna component for easy invocation
- Invariant to format, rotation, scale, translation, illumination, resolution, cropping, warping and distortions
- May be applied to wide range of image
collections, not just print images.
More information: www.scape-project.eu/tools

