When dealing with large volumes of files, e.g. in the context of file format migration or file characterisation tasks, a standalone server often cannot provide sufficient throughput to process the data in a feasible period of time. ToMaR provides a simple and flexible solution to run preservation tools on a Hadoop MapReduce cluster in a scalable fashion.
ToMaR enables the use of existing command-line tools and Java applications in Hadoop’s distributed environment in a similar way to a Desktop computer without needing to rewrite the tools to take advantage of the specialised environment. By utilizing SCAPE tool specification documents, ToMaR allows users to specify complex command-line patterns as simple keywords, which can be executed on a computer cluster or a single machine. ToMaR is a generic MapReduce application which does not require any programming skills.
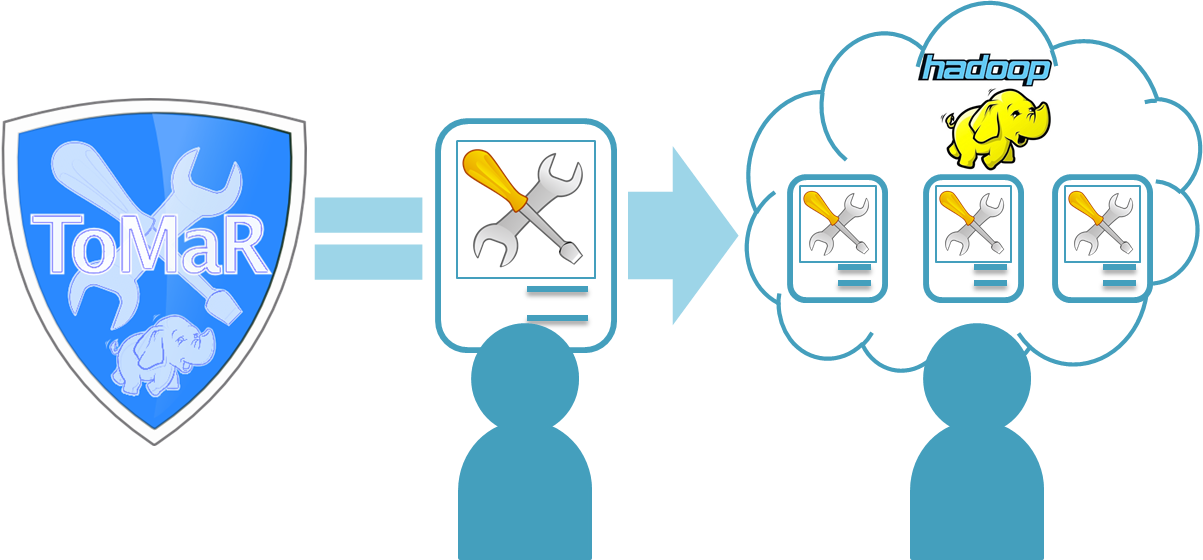
What is ToMaR?
With ToMaR you can
- Run existing tools like FITS or Jpylyzer against large amounts of files
- execute tools in a scalable fashion on a MapReduce cluster
- enable scalable workflows which chain together a set of different tools like Fits, Apache Tika, Droid, Unix File
- process payloads that are simply too big to be computed on a single machine.
What are the benefits?
- Easy take up of external tools with a clear mapping between the instructions and the physical invocation of the tool
- Use the SCAPE Toolspec, as well as other existing Toolspecs
- Associate simple keywords with complex command-line patterns
- No specific programming skills are required as only a control file needs to be set up per job.
More information: www.scape-project.eu/tools

