Flint is a framework to facilitate a configurable file/format validation. Its underlying architecture is based on the idea that file/format validation almost always has a specific use-case with concrete requirements that may differ from a validation against the official industry standard of a given format. In order to match such requirements Flint was developed.
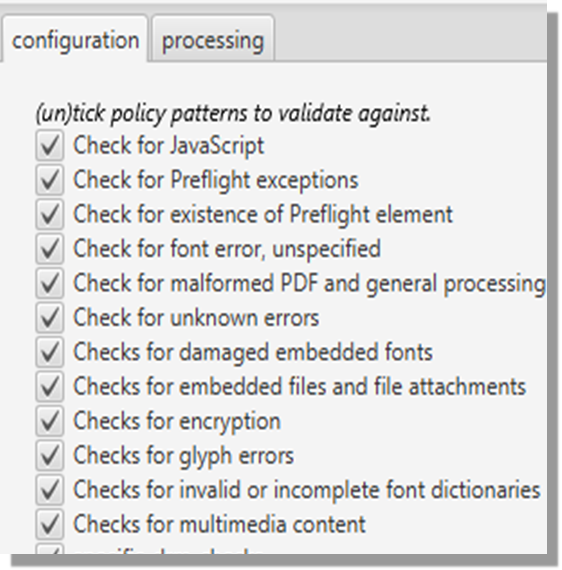
Flint allows you to determine your own institutional policy and identify files that fall outside it, for example PDFs with missing embedded fonts, or files that are not valid. The approach taken is that it is better to aggregate information from several sources, so the PDF and EPUB modules reuse several external programs and libraries including: Apache Tika, Apache PDFBox, IDPF EpubCheck, Jhove, Calibre and iText. The core module provides an interface for new format-specific implementations, which makes it easy to write a new module to add other file formats as well.
Ways you can use Flint
Flint comes with several ‘entry points’ that make use of the core functionality:
- A Command Line Interface (flint-cli)
- A simple GUI, using JavaFX8 (flint-fx)
- A Hadoop MapReduce module (flint-hadoop).
What is Flint?
Flint is a modular and extendible file/format
validation framework which:
- Detects DRM and encryption within PDF and EPUB files
- Helps you determine your own institutional policy and identify files that fall outside it
- Encapsulates external libraries API’s in wrappers to isolate complexity from the main program and facilitate reuse.
What are the benefits?
- Lightweight framework
- Fast tests
- Existing modules for PDF and EPUB
- Simple API to add new file formats
- Modules in development for some geospatial file formats
- Policy is kept in configuration files, separate from code.
More information
http://flint.openplanetsfoundation.org/

